[DB] SQL (2)
2022. 10. 14. 00:47ㆍDB
1. SQL CREATE TABLE
| INTEGER or INT | |
| CHAR(n) | |
| FLOAT | |
| DATE | YYYY - MM - DD 형식으로 년,월,일으로 구성 |
| TIME | HH : MM : SS 형식으로 시,분,초로 구성 |
| TIMESTAMP (DATETIME) | DATE + TIME 형 |
2. SQL DML

SELECT
가장 기본이 되는 건 SELECT와 FROM이다.
- SELECT - 전체 schema 에서 무엇을/전체를 출력할지 정함.
- DISTINCT - 똑같은 rows를 제거함. ex) 전체 중에 name과 age만 출력한다면 똑같은 row가 있을 수도 있음.

위 Table에서 나이만 다른 Mike Olson이 있는데, SELECT Sailors.name, Sailors.dept 로 설정하면

다음과 같이 중복된 값이 나온다. 이럴 때 DISTINCT를 사용하면

이런식으로 중복값이 제거된 Output을 볼 수 있다.
FROM
- FROM - 어디 Table에서 데이터를 찾을건지 결정함.
- AS name 을 통해 긴 Table 이름을 간략하게 줄여 표현할 수 있다.
- ex) FROM Sailors AS S
WHERE
- WHERE - 데이터 중에서 찾고자 하는 조건을 의미함.
- ex) WHERE Sailors.age = 27
ORDER BY
- ORDER BY - 출력될 데이터들을 정렬해줌.


- 위 표처럼 2가지 이상의 order 기준을 넣을 수도 있다. 이렇게 설정할 시 gpa > 나이 순으로으로 출력해준다.
- 또한 Lexicographic ordering도 지원한다.


- increasing / descending order 모두 할 수 있다. ASC(오름차순)이 기본이기 때문에 asc는 입력하지 않아도 된다. 내림차순을 원하면 ORDER BY 맨 마지막에 desc를 추가하면 된다.
LIMIT
- LIMIT - instance가 너무 많으니 n개의 rows만 출력하겠다는 의미
- 주로 ORDER BY와 함께 쓰인다. ORDER BY가 없이 LIMIT를 사용하면 출력이 비결정적이다.
AGGREGATES
- AGGREGATES - 출력하기 전, 결과의 요약을 계산해서 보여줌.


- AVG, SUM, COUNT, MAX, MIN 등이 있음.
- S.gpa로 작성해도 되고, gps라고만 작성해도 된다.
- DISTINCT AGGREGATES
- 위에 DISTINCT에서 나왔던 같은 이름의 데이터때문에 나온 기능이다.
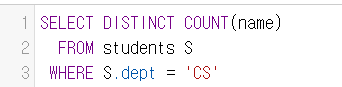
- 아래 첫번째의 출력은 5, 2번째의 출력은 6이다. 첫번째는 이름에 DISTINCT를 하여 중복된 이름을 없애고 COUNT했고, 2번째는 전체에 DISTINCT를 하고 COUNT를 했기 때문에, 이름은 같지만 나이가 다른 데이터가 중복처리 되지 않아 삭제되지 않았기 때문이다.
- DISTINCT AGGREGATES

GROUP BY
- GROUP BY - 그룹별 통계를 낼 때 사용


HAVING
- HAVING - 그룹핑 한 후 에 그룹별로 의미를 따져서, 조건에 참인 그룹만 살아남음
- GROUP BY & AGGREGATES 다음에 HAVING을 한다.
- 아래 첫번째 사진 속 형광펜을 칠한 부분이 그룹의 생존조건이다.


'DB' 카테고리의 다른 글
| [DB] SQL (1) (1) | 2022.10.13 |
|---|---|
| ER - model (0) | 2022.10.13 |